Hyperparameter optimization¶
Next, we will consider optimization of the model hyperparameters, in order to use a better optimized model with a selected feature set to minimize the model errors. To do this, we need to add the HyperOpt section to our input file, as shown below. Here, we are optimzing our KernelRidge model, specifically its root_mean_squared_error, by using our RepeatedKFold random leave-out cross-validation scheme. The param_names field provides the parameter names to optimize. Here, we are optimizing the KernelRidge alpha and gamma parameters. Parameters must be delineated with a semicolon. The param_values field provides a bound on the values to search over. Here, the minimum value is -5, max is 5, 100 points are analyzed, and the numerical scaling is logarithmic, meaning it ranges from 10^-5 to 10^5. If “lin” instead of “log” would have been specified, the scale would be linear with 100 values ranging from -5 to 5.
Example:
[HyperOpt]
[[GridSearch]]
estimator = KernelRidge
cv = RepeatedKFold
param_names = alpha ; gamma
param_values = -5 5 100 log float ; -5 5 100 log float
scoring = root_mean_squared_error
Let’s take a final look at the same full fit and RepeatedKFold random cross-validation tests for this run:
Full-fit:
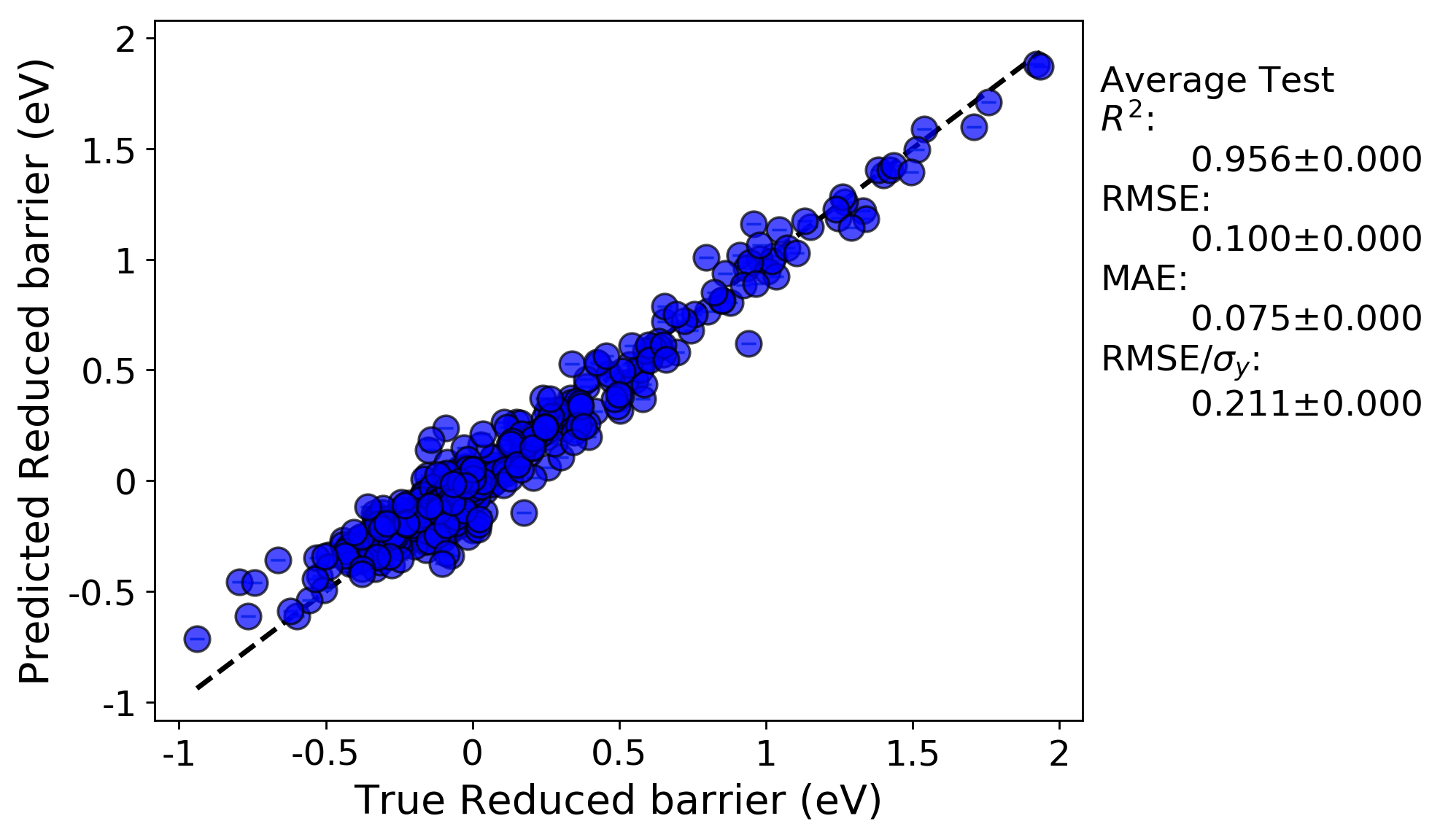
Random leave out cross-validation:
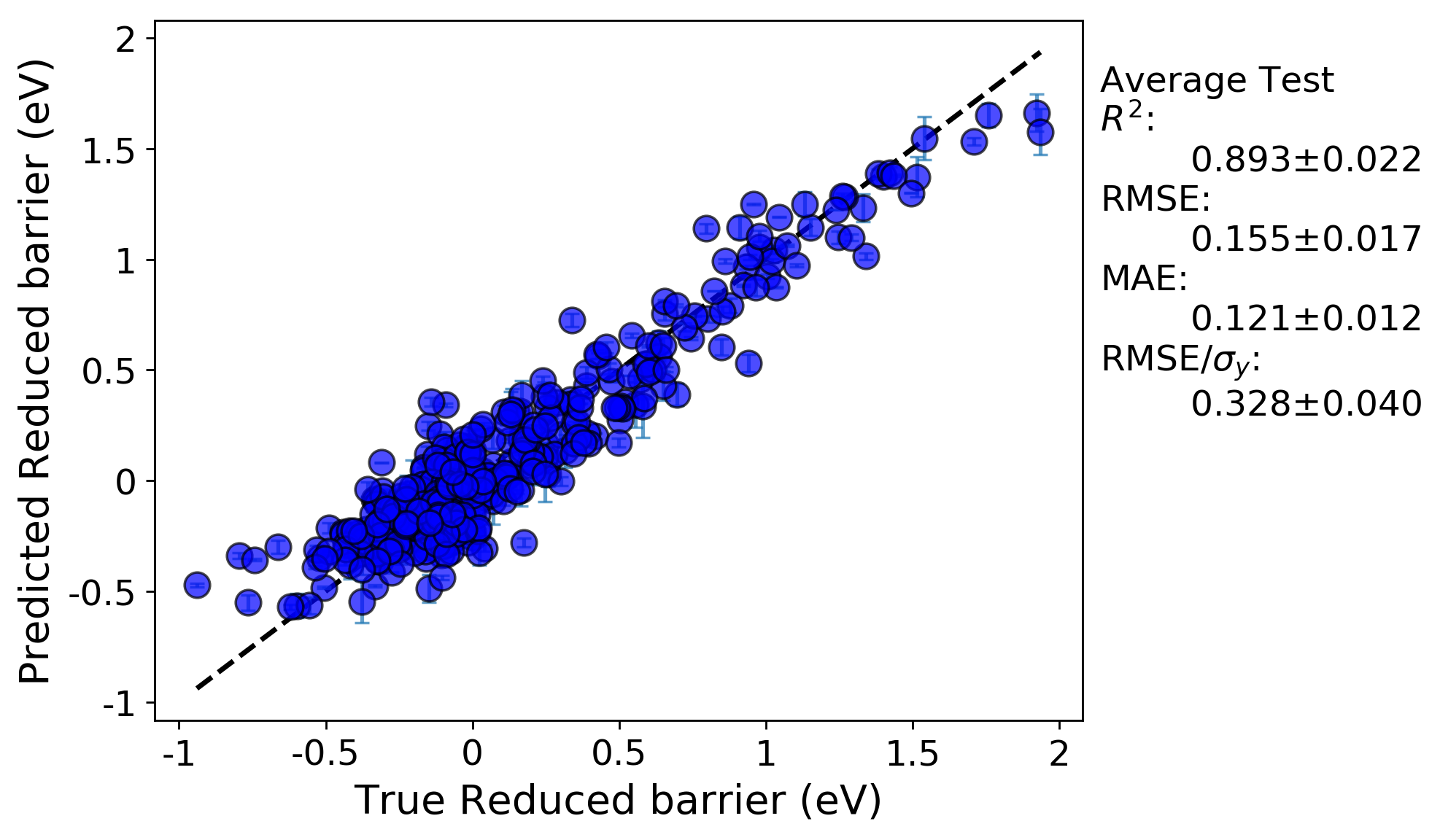
What we can see is, now that we down-selected features from more than 300 features in the previous run to just 20, along with optimizing the hyperparameters of our KernelRidge model, our fits are once again improved. The hyperparameter optimization portion of this workflow outputs the hyperparameter values and cross-validation scores for each step of, in this case, the GridSearch that we performed. All of this information is saved in the KerenlRidge.csv file in the GridSearch folder in the results directory tree. For this run, the optimal hyperparameters were alpha = 0.034 and gamma = 0.138